Since the emergence of Large Language Models (LLMs), implementing locally deployed knowledge bases using LLM+RAG has become a hot topic.
This article will provide a complete guide to deploying an LLM+RAG knowledge base system on Ubuntu 24.04 and share tuning tips to help developers build efficient, private AI knowledge bases.
Basic Information Overview
Overview of Ollama
Ollama is an open-source tool designed to simplify the process of running large language models (LLMs) locally. It supports various models like Llama 2, Mistral, etc., and provides a user-friendly interface, suitable for developers or researchers using LLMs in a local environment. Its main advantages are data privacy and local execution, reducing reliance on cloud services.
Overview of AnythingLLM
AnythingLLM is a full-featured AI application supporting RAG (Retrieval-Augmented Generation), AI agents, and document management. It allows users to choose different LLM providers (like Ollama, OpenAI, etc.) and embedding models, making it suitable for building private knowledge bases. Its desktop version supports Linux, Windows, and macOS, emphasizing local execution and multi-user management.
Overview of DeepSeek V3 Model
DeepSeek V3 is an open-source large language model (LLM) developed by DeepSeek. It employs a Mixture-of-Experts (MoE) language model architecture with a total of 671 billion parameters, activating 37 billion parameters per inference. By activating only a portion of the expert network, it achieves computational efficiency, reducing computational costs for inference and training.
Overview of DeepSeek-R1-Distill-Llama-70B Model
DeepSeek R1 is a large language model (LLM) developed by the Chinese AI company DeepSeek, focusing on areas like logical reasoning, mathematics, and coding. It utilizes a Mixture-of-Experts (MoE) architecture with a total of 67.1 billion parameters.
In addition to releasing the DeepSeek R1 model itself, DeepSeek has also open-sourced several distilled models. These distilled models are created by transferring the knowledge from DeepSeek R1 into smaller open-source models, aiming to retain most of the performance while reducing model size and improving computational efficiency.
Overview of QwQ-32B Model
QwQ-32B is an inference model developed by the Qwen team (Alibaba Cloud) with 32.5 billion parameters, excelling at coding and mathematical reasoning. The model supports long contexts (up to 131K tokens), making it suitable for complex tasks, but requires at least 24GB of GPU memory to run (when quantized).
Overview of Bge-m3 Embedding Model
Bge-m3 is an embedding model developed by BAAI (Beijing Academy of Artificial Intelligence). It supports multifunctionality (dense retrieval, multi-vector retrieval, sparse retrieval), multilingual capabilities (100+ languages), and multi-granularity (from short sentences to 8192 token documents). It excels in multilingual retrieval tasks and is suitable for document embedding in knowledge bases.
Deployment Prerequisites
Software Environment
- System: Ubuntu 24.04 (Latest LTS version recommended)
Hardware Requirements
- GPU memory: At least 16GB; If sufficient GPU memory is unavailable, lower quantized versions of the models can be used.
- Sufficient disk space to store model files and knowledge base data.
Deployment Process
Install Ollama
Detailed documentation can be found in the Official Ollama Documentation
Installation
- Open a terminal and execute the following command:
curl -fsSL https://ollama.com/install.sh | sh - Start the ollama service:
ollama serve - Verify ollama version:
ollama --version - List locally downloaded models:
ollama list
Set up Service Autostart
- Create user and group:
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama sudo usermod -a -G ollama $(whoami) - Create the service file /etc/systemd/system/ollama.service:
sudo vim /etc/systemd/system/ollama.service - Add the following content to the file:
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=$PATH" [Install] WantedBy=multi-user.target - After saving the file modifications, execute:
sudo systemctl daemon-reload sudo systemctl enable ollama
Configuration
- By default, Ollama runs with the API service address http://127.0.0.1:11434. If you need to allow API access from other URLs, you can configure the environment variable:
sudo vim /etc/systemd/system/ollama.service - Add the Environment configuration under the
[Service]section in the file:[Service] Environment="OLLAMA_HOST=0.0.0.0:11434" - After saving the file modifications, execute:
sudo systemctl daemon-reload sudo systemctl restart ollama
Download LLM Models
Download QwQ-32B Model
- Run the following command in the terminal and wait for the download to complete:
ollama pull qwq - Check if the model already exists:
ollama list
Download DeepSeek R1 Model
- Run the following command in the terminal and wait for the download to complete. By default, this downloads the 4-bit quantized model:
ollama pull deepseek-r1:1.5b // Download 1.5b model ollama pull deepseek-r1:7b // Download 7b model ollama pull deepseek-r1:8b // Download 8b model ollama pull deepseek-r1:14b // Download 14b model ollama pull deepseek-r1:32b // Download 32b model ollama pull deepseek-r1:70b // Download 70b model - To download non-quantized models, use the following command:
ollama pull deepseek-r1:32b-qwen-distill-fp16
Download Embedding Models
Download Bge-m3 Model
- Run the following command in the terminal and wait for the download to complete:
ollama pull bge-m3
Install and Deploy AnythingLLM
AnythingLLM has a desktop version available for download from the Desktop Download Page . Download the version corresponding to your operating system, install it, and run it directly.
If you need to deploy the server version to support multiple users, use the following commands:
Installation
- Set the AnythingLLM installation directory:
sudo mkdir -p /home/anythingllm && cd /home/anythingllm - Download the Docker image:
docker pull mintplexlabs/anythingllm:master - Set environment variables:
export STORAGE_LOCATION="/home/anythingllm" && touch "$STORAGE_LOCATION/.env" - Run the container:
docker run -d -p 3001:3001 --cap-add SYS_ADMIN -v ${STORAGE_LOCATION}:/app/server/storage -v ${STORAGE_LOCATION}/.env:/app/server/.env -e STORAGE_DIR="/app/server/storage" --add-host=host.docker.internal:host-gateway mintplexlabs/anythingllm:master
Configuration
-
Access http://<YOUR_REACHABLE_IP>:3001/ to configure.
 Click the icon in the bottom left corner of the page to enter the configuration page and begin AnythingLLM setup.
Click the icon in the bottom left corner of the page to enter the configuration page and begin AnythingLLM setup. -
Configure Admin User:
 On the initial login, you need to enter a username and password, then proceed with the configuration. Once configured, you can access it via http://<YOUR_REACHABLE_IP>:3001/.
On the initial login, you need to enter a username and password, then proceed with the configuration. Once configured, you can access it via http://<YOUR_REACHABLE_IP>:3001/. -
Configure LLM Preference:
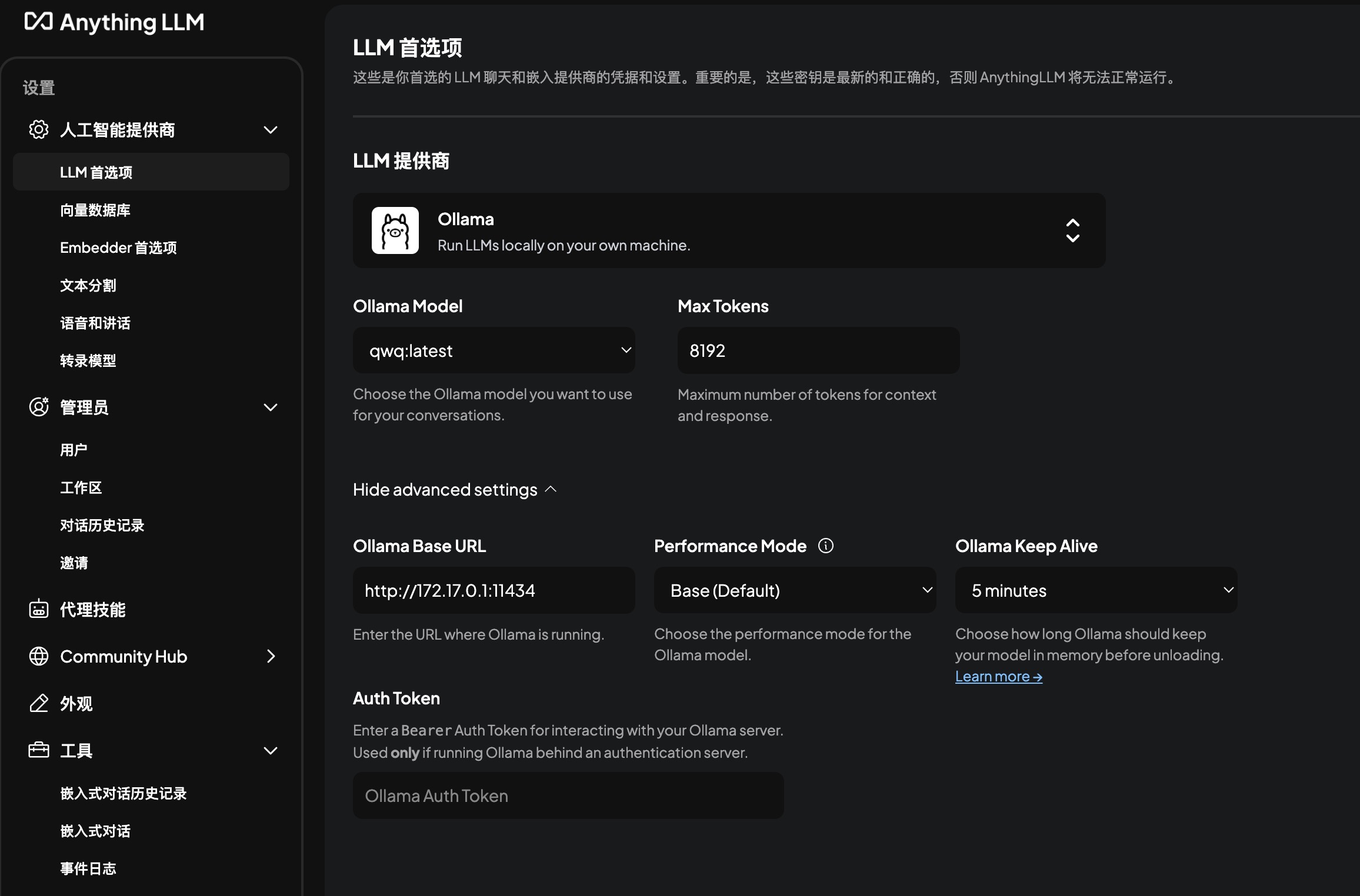 The “LLM Provider” option allows selecting Ollama, OpenAI, etc.
The “LLM Provider” option allows selecting Ollama, OpenAI, etc.- If choosing an external model like OpenAI, configure the API Key.
- If selecting Ollama, note that for AnythingLLM running via Docker, the Ollama Base URL is http://172.17.0.1:11434.
If the Ollama service connects successfully, the Ollama Model option will display a list of available models. Currently selected:
qwq:latest. -
Embedder Preference:
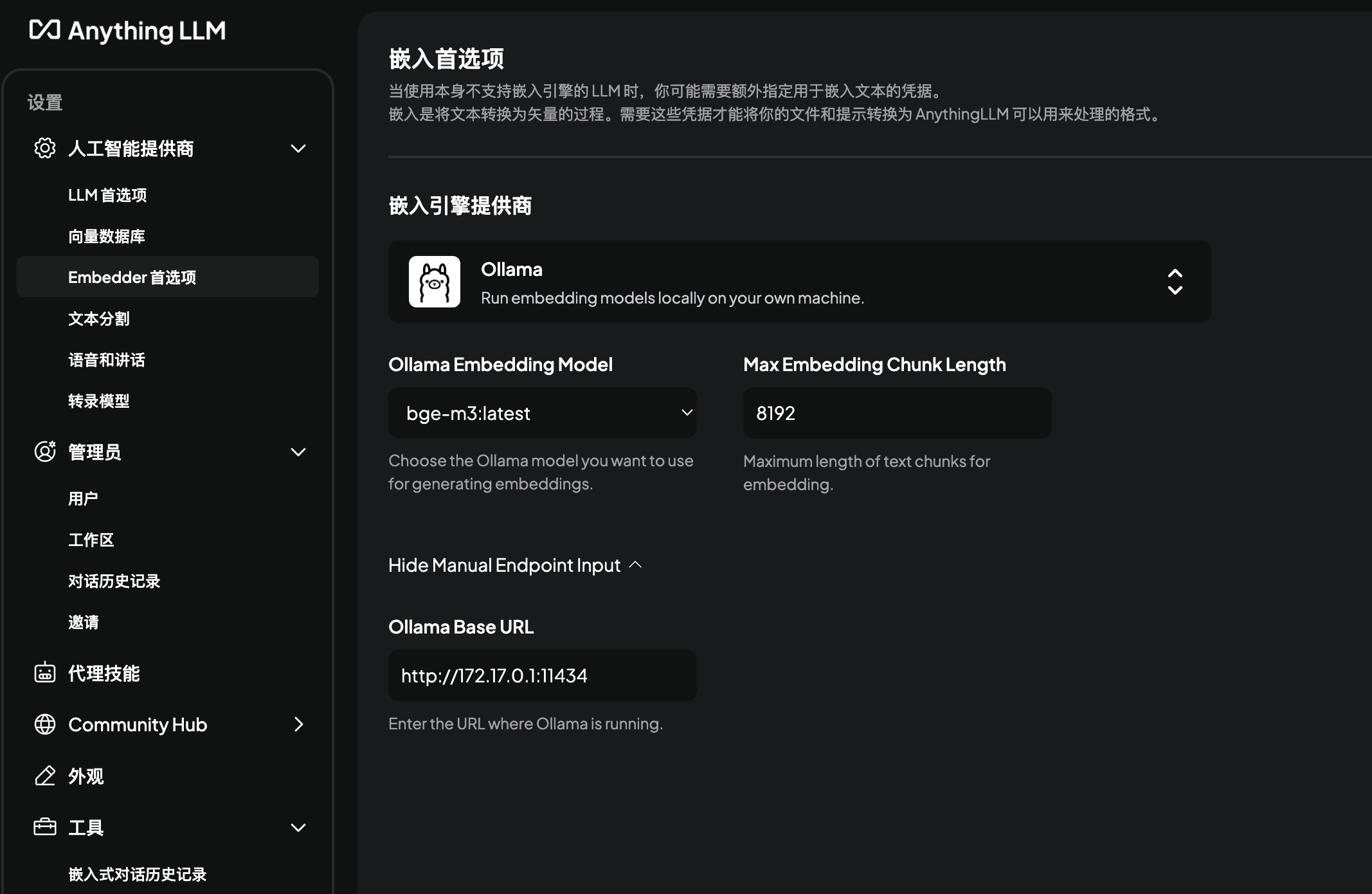 The “Embedding Engine Provider” allows selecting AnythingLLM’s default embedding engine, Ollama, or other third-party services.
The “Embedding Engine Provider” allows selecting AnythingLLM’s default embedding engine, Ollama, or other third-party services.- AnythingLLM’s default embedding engine is
all-MiniLM-L6-v2, which is primarily optimized for English documents and has limited multilingual support. - If choosing other third-party services like OpenAI, you need to configure the API Key.
- If selecting Ollama, note that for AnythingLLM running via Docker, the Ollama Base URL is http://172.17.0.1:11434.
If the Ollama service connects successfully, the Ollama Model option will display a list of available models. Currently selected:
bge-m3:latest. - AnythingLLM’s default embedding engine is
-
Finish Configuration and Return to Main Page:
Creating a Local Knowledge Base
Data files uploaded in AnythingLLM can be used by multiple knowledge bases.
The process for creating a new knowledge base is as follows:
Create a new workspace -> Upload or select existing data files -> Add data files to the workspace -> Vectorize data
Once data vectorization is complete, the knowledge base for that workspace is created.
Create New Workspace
-
New Workspace
Click the “New Workspace” button and name the new workspace.
-
Workspace Settings
 Click the icon to enter the workspace settings page.
Click the icon to enter the workspace settings page.
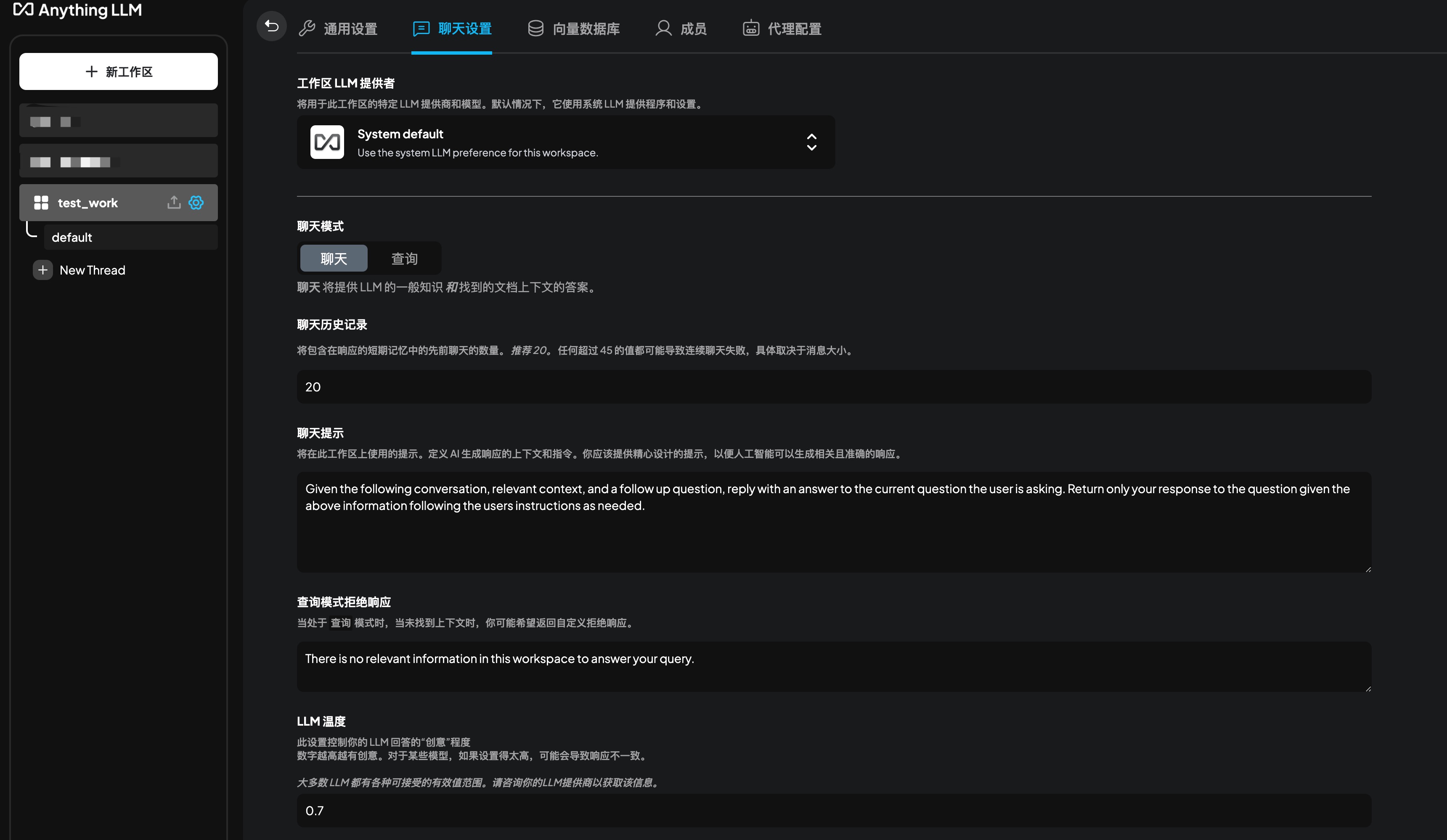 Select Ollama for “Workspace LLM Provider”. This will display the “Workspace Chat Model” option, where you can choose the desired model. Currently selected:
Select Ollama for “Workspace LLM Provider”. This will display the “Workspace Chat Model” option, where you can choose the desired model. Currently selected: qwq:latest.Use default values for other workspace configurations.
Upload Local Files
- Open Upload Files Dialog
 Click the icon shown in the image to open the upload files dialog.
Click the icon shown in the image to open the upload files dialog. - Upload Files and Complete Vectorization
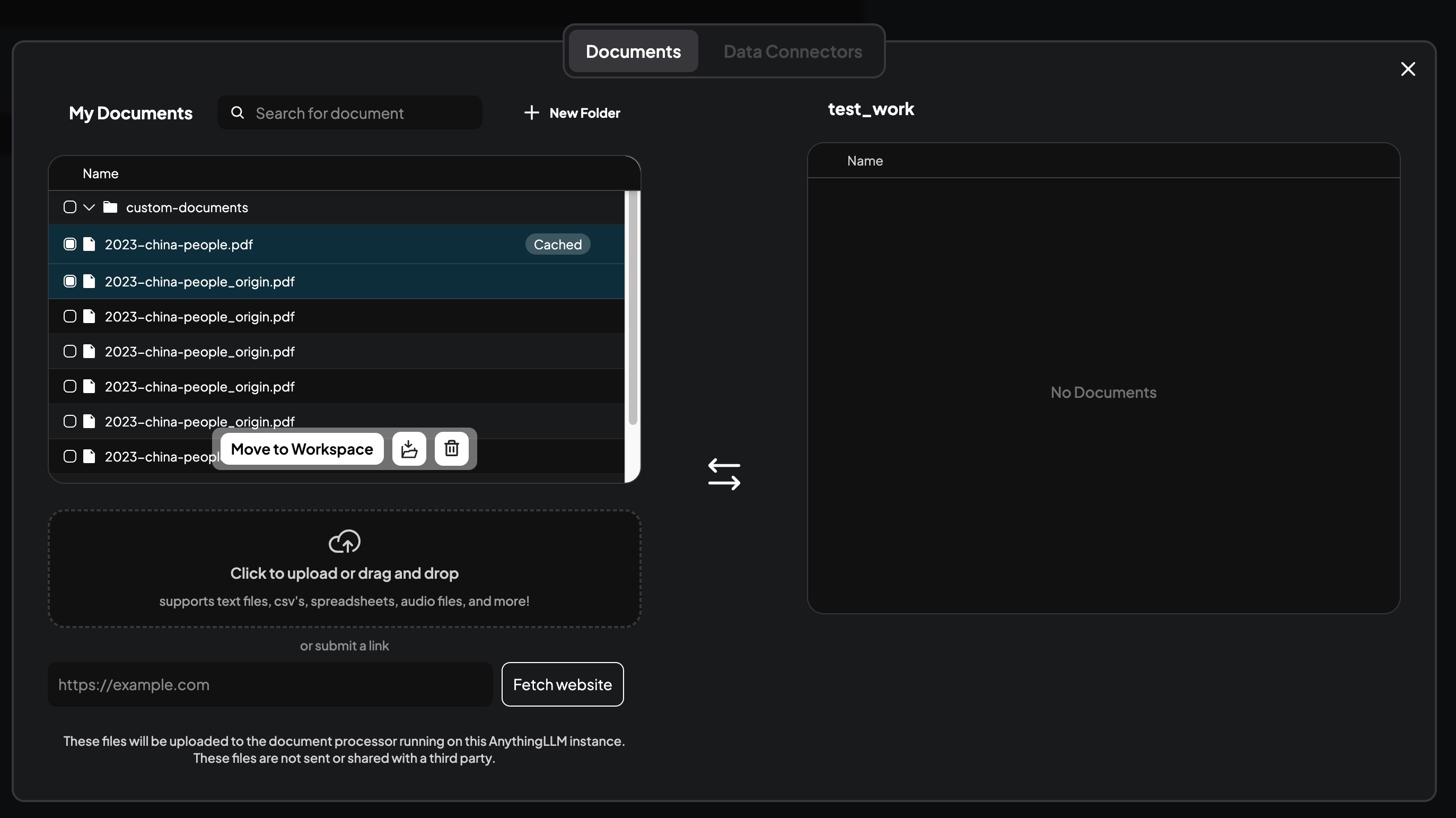
- Drag and drop the files you want to import into the knowledge base into the upload dialog.
- Select the knowledge base data files you wish to import into the workspace from the list.
- Click the “Move to Workspace” button to import the selected files into the workspace.
- Click the “Save and Embed” button and wait for the system to vectorize the data. Data vectorization is now complete.
Tuning the Local Knowledge Base
Embedding Vector Model Selection
Different embedding vector models have different characteristics:
| Feature | all-MiniLM-L6-v2 | BAAI/bge-m3 |
|---|---|---|
| Model Size | 25MB | ~1.5GB |
| Hardware Req. | Runs on CPU, >=2GB RAM | GPU recommended |
| Multilingual Task | Primarily English | Supports >100 languages |
| Inference Speed (CPU) | Fast, good for low-end | Slower, GPU recommended |
Text Chunk Size and Overlap Selection
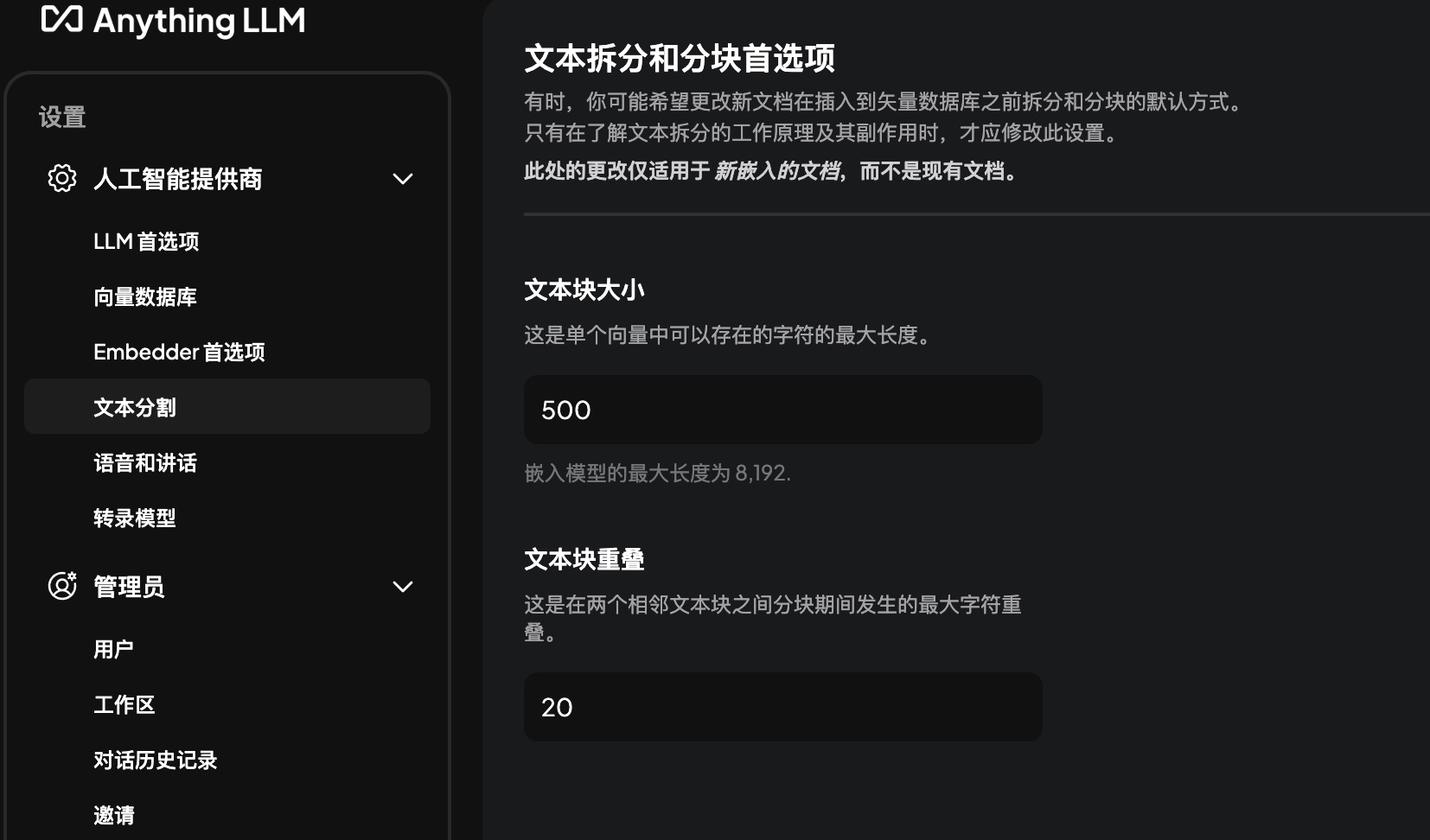
A text chunk refers to a smaller segment of a document after it has been split, often necessary due to the input length limitations of Large Language Models (LLMs).
Overlap refers to the shared portion between adjacent chunks, intended to maintain contextual continuity and prevent loss of information at boundaries.
-
Impact of Text Chunk Size Chunk size directly affects the semantic representation of vectors and downstream task performance:
- Contextual Understanding: Very small chunks might not capture sufficient context.
- Computational Efficiency: Larger chunks require more computational resources; increased input length significantly raises processing time.
- Granularity and Task Matching: Smaller chunks are suitable for tasks needing fine-grained information (e.g., specific information retrieval); larger chunks are better for tasks requiring overall context (e.g., document summarization).
-
Impact of Overlap Amount Overlap ensures contextual continuity at chunk boundaries:
- Context Preservation: Overlap helps prevent information loss, e.g., a sentence spanning across chunks remains intact through overlap.
- Redundancy vs. Efficiency: Excessive overlap (e.g., >20%) increases computational cost.
- Task Relevance: The amount of overlap should be adjusted based on the task. For instance, in information retrieval, overlap ensures queries match information near chunk boundaries; in question-answering systems, overlap helps maintain context integrity.
The choice of text chunk size and overlap can be adjusted based on the task and hardware environment. Different types of text may require different strategies. For example, technical documents might benefit from smaller chunks to capture details, while narrative texts might need larger chunks to maintain story context.
Chat Prompt Optimization
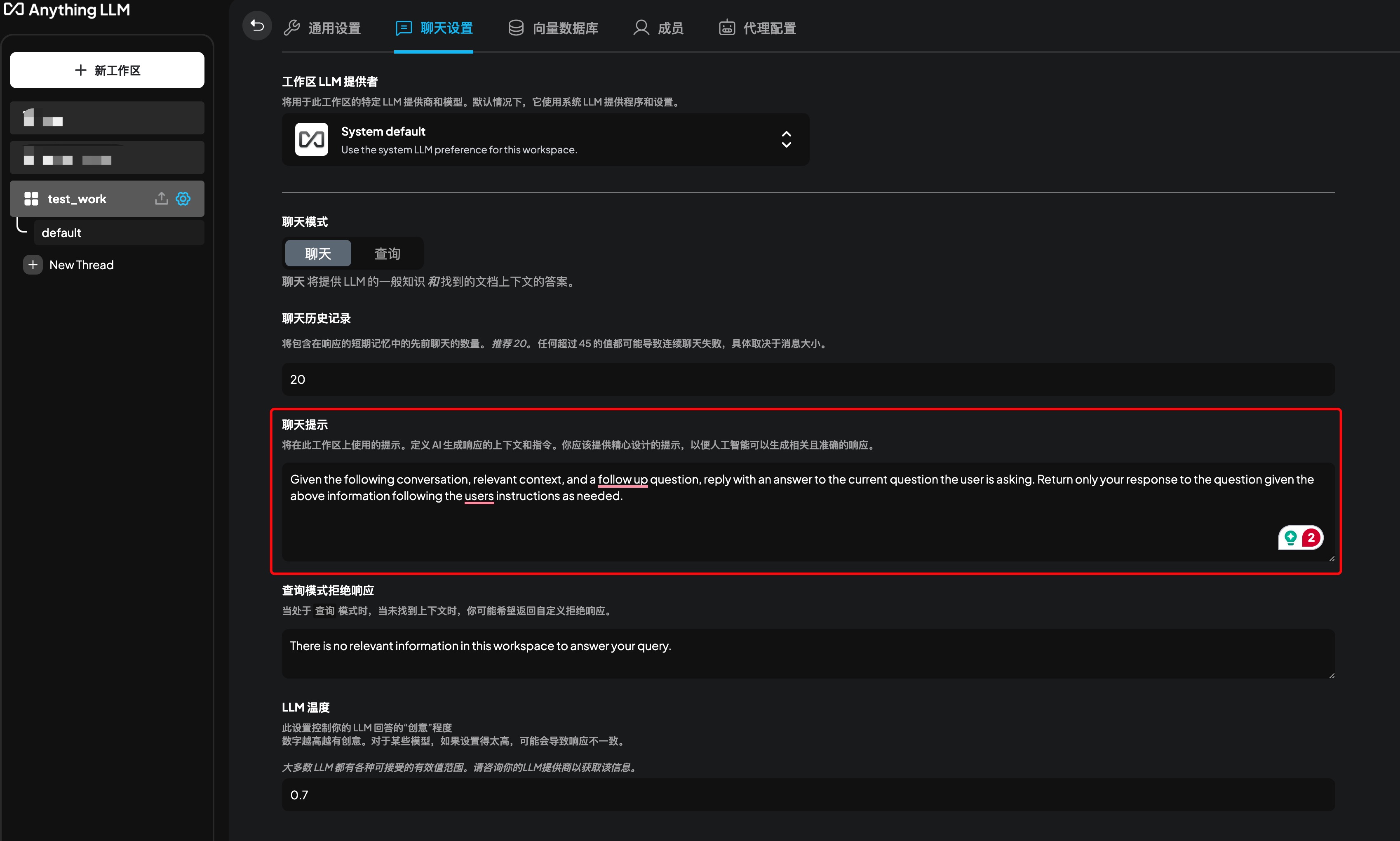 Prompts for the LLM chat model are used to control the model’s behavior, helping it better understand and answer questions.
Prompts for the LLM chat model are used to control the model’s behavior, helping it better understand and answer questions.
LLM Temperature Setting
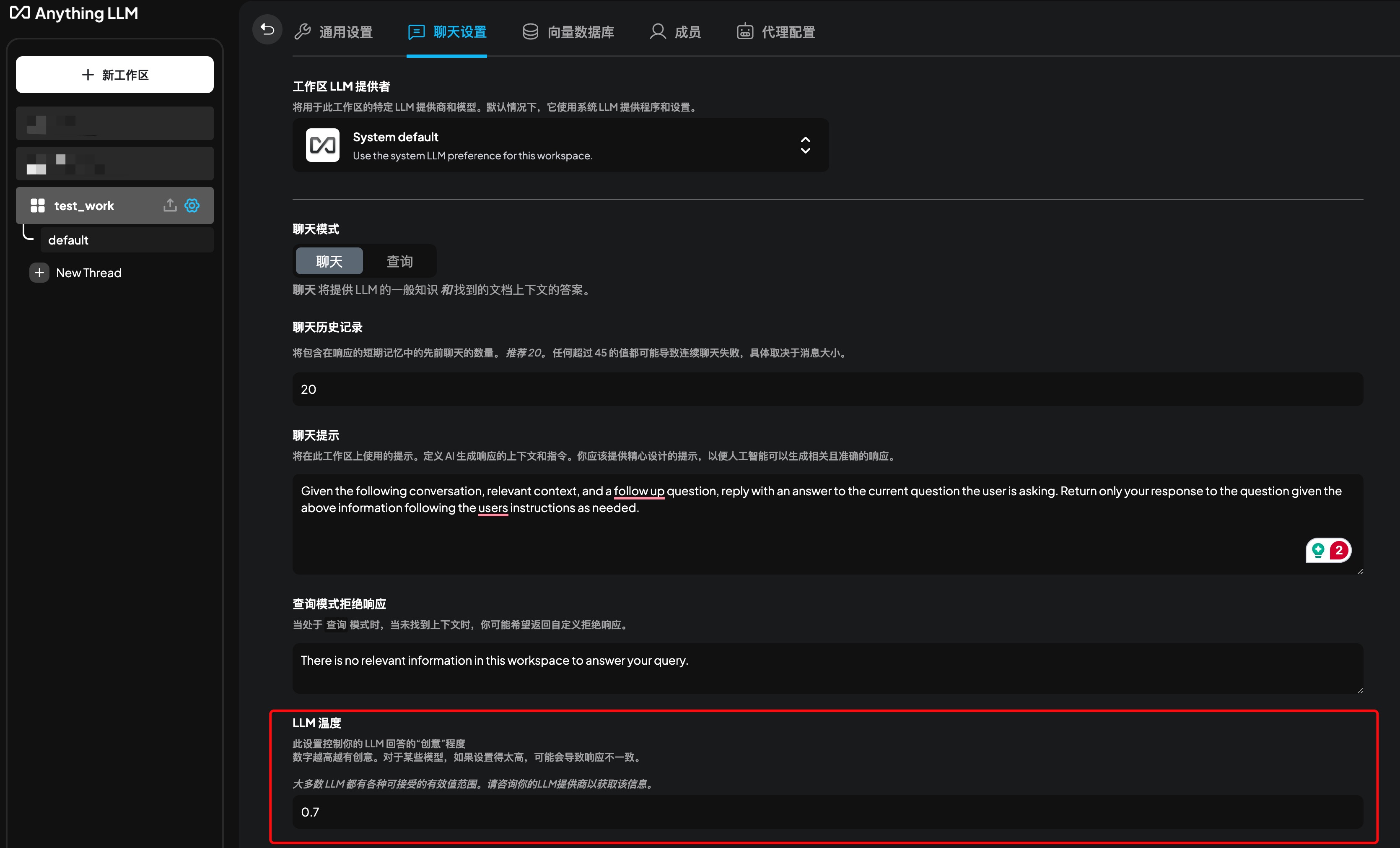 The LLM temperature setting controls the model’s randomness, allowing for better control over the quality of the output.
The LLM temperature setting controls the model’s randomness, allowing for better control over the quality of the output.
Vector Database Settings
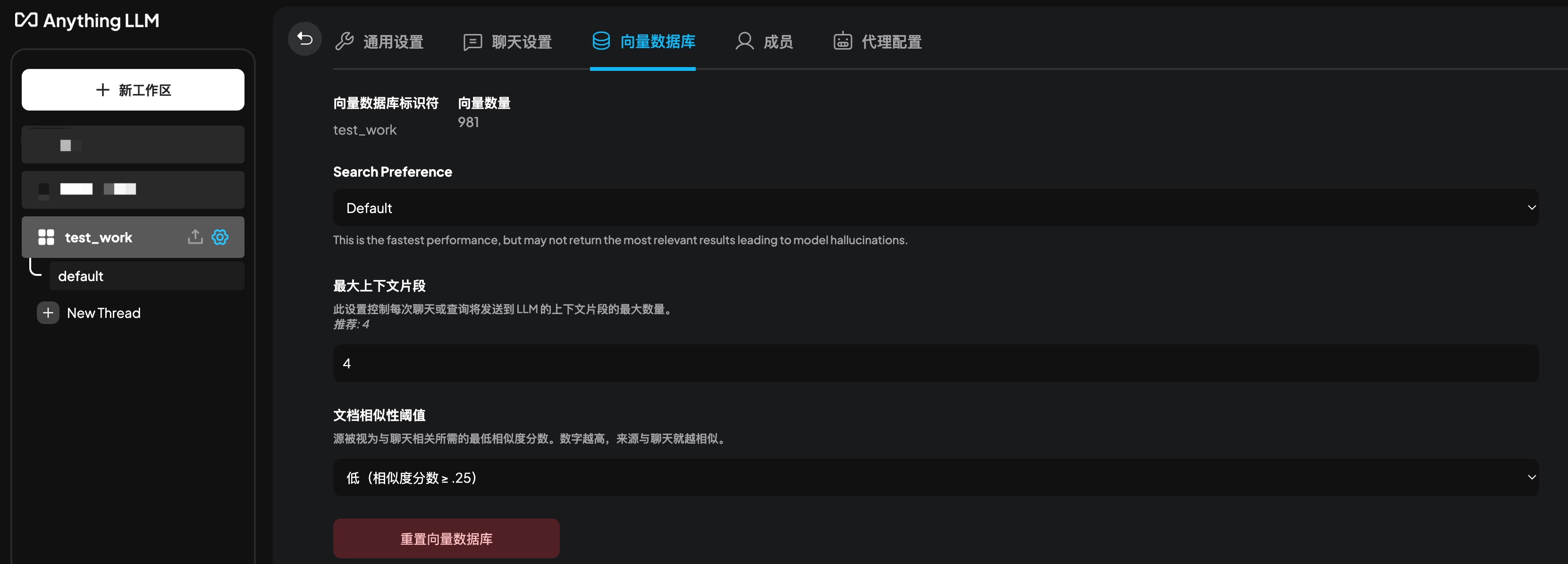
- Max Context Chunks: Controls the number of context chunks sent to the LLM with each request. A higher number means the LLM receives more data, potentially improving result quality but requiring more computational resources.
- Document Similarity Threshold: Controls the similarity between documents. A higher threshold means returned results are more strongly related to the source documents, but if retrieval yields few results, it might lead to inaccurate answers.